
Sommaire
La deduplication est arrivée il y a maintenant quelques releases Windows Server. Le but de ce billet n’étant pas de comprendre le concept de la deduplication, Microsoft le fait très bien par ici, https://technet.microsoft.com/fr-fr/library/Hh831602.aspx , nous verrons ensemble comment mettre en place et configurer la fonction sur Windows Server 2012R2.
Installation du rôle Data Deduplication
Exécutez la console « Server Manager ».
Cliquez sur « Add Roles and Features » et au niveau des paramètres Server Roles, sélectionnez « Data Deduplication ». (Laissez le reste par défaut pour l’installation).
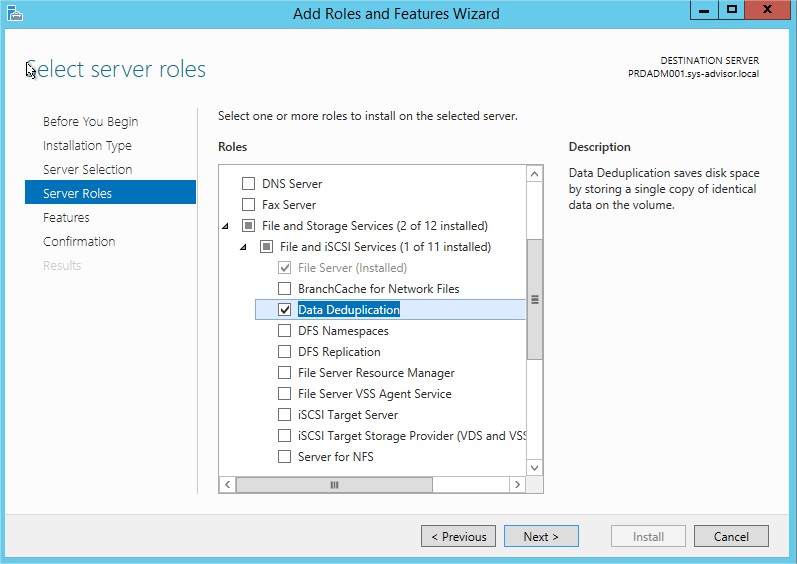
Configuration du rôle Data Deduplication
Toujours depuis la console « Server Manager », rendez-vous au niveau du rôle « File and Storage Services » partie « Volumes ».
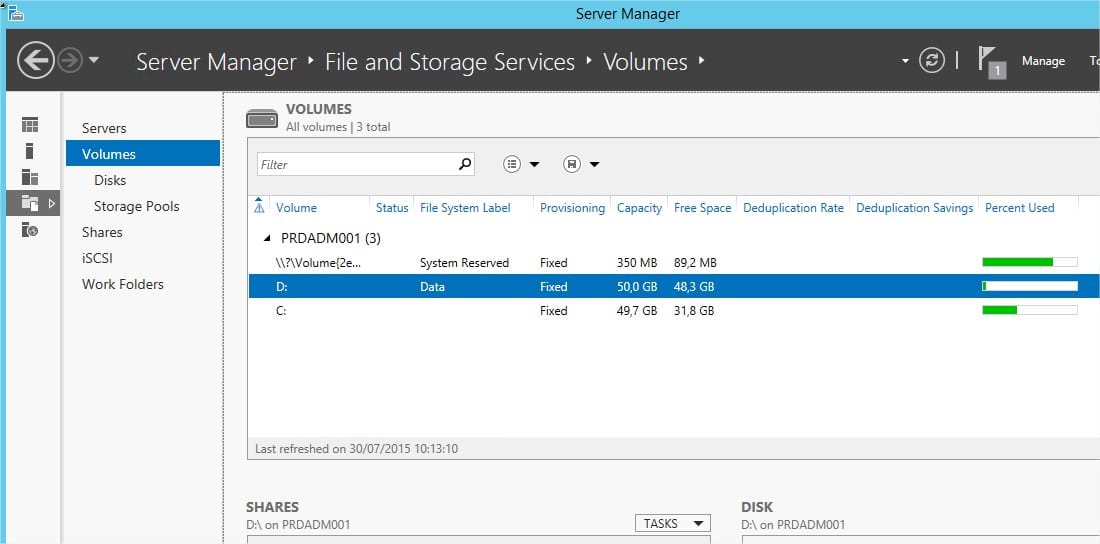
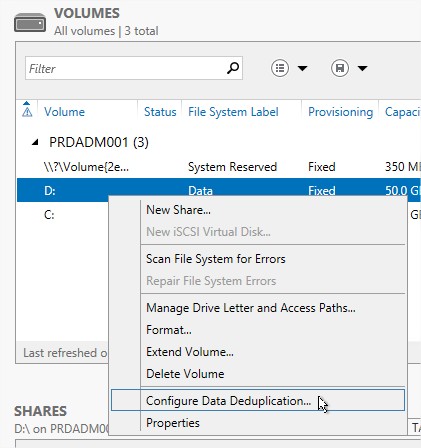
Cliquez droit sur le volume ou vous souhaitez appliquer la deduplication puis sélectionnez « Configure Data Deduplication »
1. Sélectionnez « General purpose file server ».
2. Saisissez « 0 » afin d’appliquer une deduplication sur tous les fichiers sans tenir compte de la date.
3. Il est possible d’exclure des fichiers en fonction de leurs extensions ou bien directement des dossiers, en fonction de vos besoins.
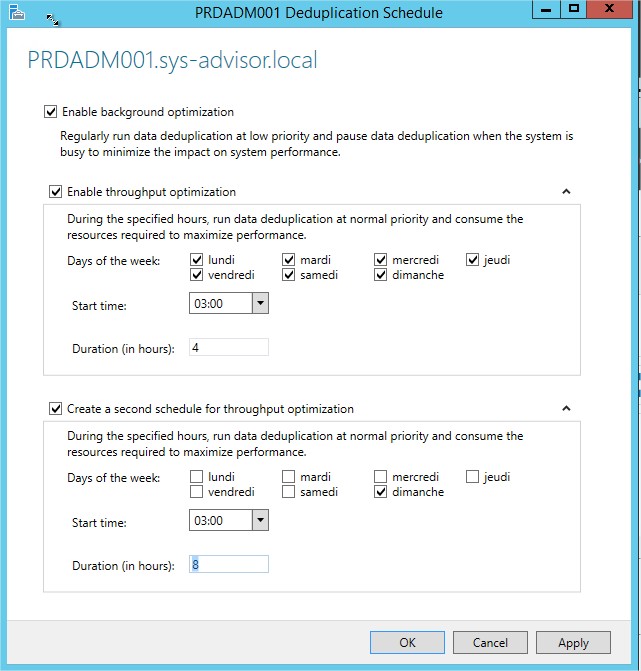
4. Cliquez sur « Set Deduplication Schedule… »
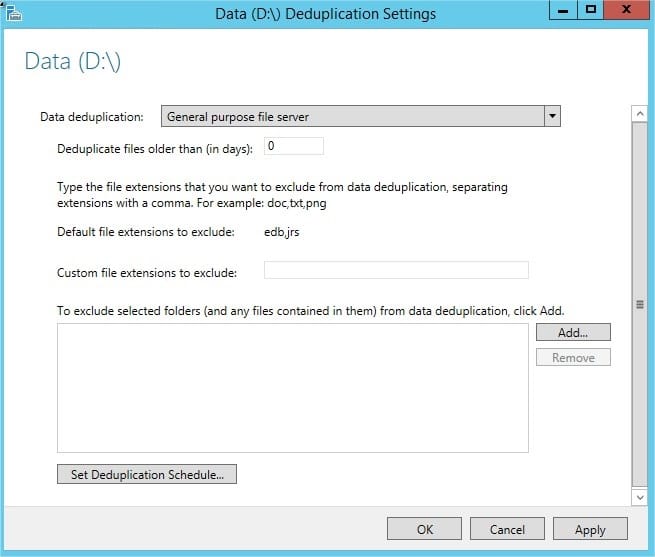
Cette partie permet de configurer la planification des jobs de deduplication.
Suivant votre situation et votre infrastructure, ces paramètres seront probablement différents.
Quelques commandes Powershell
Pour exécuter manuellement les jobs de deduplication.
Start-DedupJob -Type Optimization -Volume D:
Pour afficher les jobs en cours d’exécution.
Get-DedupJob
Pour afficher le status de la Deduplication appliquée.
Get-DedupStatus










References:
Casino Film 1995 https://spins-casino.online-spielhallen.de/
References:
Politikuri tamashi https://online-casino-guru.online-spielhallen.de/
References:
Legends casino https://prpack.ru/user/smellbolt92/
online poker real money paypal
References:
http://chansolburn.com/bbs/board.php?bo_table=free&wr_id=1347724
us online casinos paypal
References:
https://wsurl.link/f57yyr
Momondo compares 3M+ hotel and accommodation options.
We believe that together we create unforgettable experiences for our guests.
We are also committed to proving a culture that motivates, challenges,
and inspires our colleagues every day.
Standard rates apply thereafter for additional guests. Cancellations for bookings must be cancelled prior to 6pm on the day prior to arrival to avoid
forfeiture of the full fee of one (1) night and applicable tax.
Blackout periods or limited availability may apply to special event periods and public holidays.
Complete with overnight accommodation, breakfast for two
and late check-out at 12pm, this package offers you the perfect inner city
escape. Make the most of your Melbourne holiday
experience by booking one of our unique accommodation packages and let us take care of the rest.
In July of 2025, the Gaming and Wagering Commission of Western Australia
recommended that Crown Perth keep its gaming license after adequate remedial efforts were made to make the casino compliant with
government gaming regulations.
References:
https://blackcoin.co/cocoa-casino-review/
Yes, Crown Perth provides both free and paid parking options, including open-air lots and multi-level covered parking facilities conveniently located near the casino and hotels.
With over 390 stylish rooms and loft-style suites, the hotel is known for its urban design, generous space,
and floor-to-ceiling windows offering stunning views of the city
or Swan River. The fitness centre features the latest Technogym equipment, while the expansive
lagoon-style pool deck offers private cabanas and poolside service.
Located in Perth, less than 1 km from Perth Concert Hall, Hyde
Perth provides accommodation with an outdoor swimming pool, private parking,
a fitness centre and a terrace. Featuring panoramic views of Perth’s city skyline and a rooftop
infinity pool, Doubletree By Hilton Perth Waterfront is situated in Elizabeth Quay, with access to
local attractions and experiences… Staying at Crown Towers Perth is an indulgent experience, with its expansive
lagoon pools, unparalleled city views, luxurious spa facilities,
state-of-the-art fitness centre and high-end boutiques.
As the sunsets and the city skyline lights up,
there is so much to see and do. Perth, Western Australia is a glorious
city in the biggest state of Australia. Explore the beautiful Rottnest Island by ferry, bike
or water, see Western Australia’s capital city from new heights with a helicopter flight or indulge yourself with a massage.
Interiors emanating an aura of sophisticated simplicity,
the Poker Room houses 15 tables, teeming with the mixed essence
of anticipation, hope, and thrill. Just show your Crown Rewards
Card when you pay or play and you can start earning points, which you can redeem for Crown experiences like dining, gaming, hotel stays and much more.
References:
https://blackcoin.co/harvest-buffet-casino-the-ultimate-online-gaming-experience/
Einen Live Chat bietet Slotpark allerdings nicht, dadurch ist es mir nicht möglich gewesen,
mit einem Mitarbeiter in Echtzeit zu kommunizieren. Auszahlungen sind wie bereits beschrieben nicht möglich, da es sich hierbei um Spielgeld handelt ohne echten Gegenwert.
So konnte ich ohne Wartezeit sofort mit dem Spiel loslegen. Sämtliche Zahlungsmethoden führen zu einer sofortigen Gutschrift auf
meinem Konto und die Slotpark Dollar wurden mir
dementsprechend gutgeschrieben. So konnte ich zum Beispiel eine Kredit- oder Debitkarte wie
Visa, Mastercard, American Express zu meinem Apple-ID-Konto hinzufügen und damit Slotpark Dollar kaufen.
In jedem Satz von Bonusspielen kann sein Symbol nicht nur andere entlang
der Gewinnlinien ersetzen, sein Porträt kann Runde um Runde gleich
komplette Walzen bedecken und damit lawinenartige Gewinne auslösen. Erscheint
der Foliant gleich dreimal auf den Walzen, erhältst du nicht nur sofort einen satten Bonus, sondern obendrein zehn Freispiele!
Slotpark Dollar können nicht gegen Geld zurückgetauscht oder in irgendeiner Form ausbezahlt,
sondern nur verwendet werden, um Spiele auf Slotpark zu spielen. Die Übersicht zeigt dir auf einen Blick jeden möglichen Rundengewinn und wird je nachdem, wie viele Gewinnlinien du gerade eingestellt hast und mit welchem Einsatz du spielen möchtest, in Echtzeit aktualisiert.
In Zusammenarbeit mit Novomatic haben wir uns alle Spielemechaniken nochmals angesehen, Optik und Sound ein wenig
poliert und geben dir die Chance, diesen Automaten kostenlos Probe zu spielen! Weiterhin wird auf fünf Walzen gespielt, entlang derer alle Gewinnsymbole sowie Scatter- und Spezialsymbole erscheinen können.
References:
https://online-spielhallen.de/umfassender-leitfaden-zu-stakes-casino-bonus-codes-und-angeboten/
Bonjour ,
Merci pour le tuto. Simple et claire, Je suis Hitojo Andriamialisoa, IT officer. En ce moment je suis entrain de migrer de windows server 2008r2 vers windows server 2016 et je suis une formation chez Microsoft. J’ai une question :
Pour Windows serveur 2008 : nous avons disque D pour le shared folders. et ce dernier sont synchronisé dans dropbox avec une volume de 1To.
Pour Windows 2016 : Tout en sachant que nous utiliserons les meme données.
1 – Est-ce que j’aurrais besoin de volume 1To si je dois dédupliquer mon donnee de 1To ?
2 – Est-ce que le déduplication reste uniquement dans le gestion de d’espace disque ou, serais-il possible de restaurer les donnés par une date enterieur ?
Merci de votre reponse. Restons disponible.